大模型技术基础
2025/6/5...大约 5 分钟
大模型技术基础
大语言模型概念
定义: 通常指具有超大规模参数的预训练模型
架构:主要为transformer解码器架构
训练:
- 预训练(base model) 建立模型的基础能力
- 数据: 海量文本数据
- 优化:预测下一个词
- 后训练 (instruct model) 增强模型的任务能力
- 数据: 大量指令数据
- 优化: SFT、RL等方法
- 下游应用
- 测速(推理)
训练阶段对比
| 对比方面 | 预训练 (Pre-training) | 后训练 (Post-training) |
|---|---|---|
| 核心目标 | 建立模型基础能力 | 将基座模型适配到具体应用场景 |
| 数据资源 | 数万亿词元的自然语言文本 | 数十万、数百万到数千万指令数据 |
| 所需算力 | 耗费百卡、千卡甚至万卡算力数月时间 (大致估计) | 耗费数十卡、数百卡数天到数十天时间 (大致估计) |
| 使用方式 | 通常为few-shot提示 | 可以直接进行zero-shot使用 |
此部分算力估计为一个大致估计,需要根据模型大小、数据数量、训练框架等多方面因素确定
大语言模型构建概览
大语言模型预训练(Pre-training)
- 使用与下游任务无关的大规模数据进行模型参数的初始训练
- 基于Transformer解码器架构,进行下一个词预测
- 数据数量、数据质量都比较关键
大语言模型后训练(Post-training)
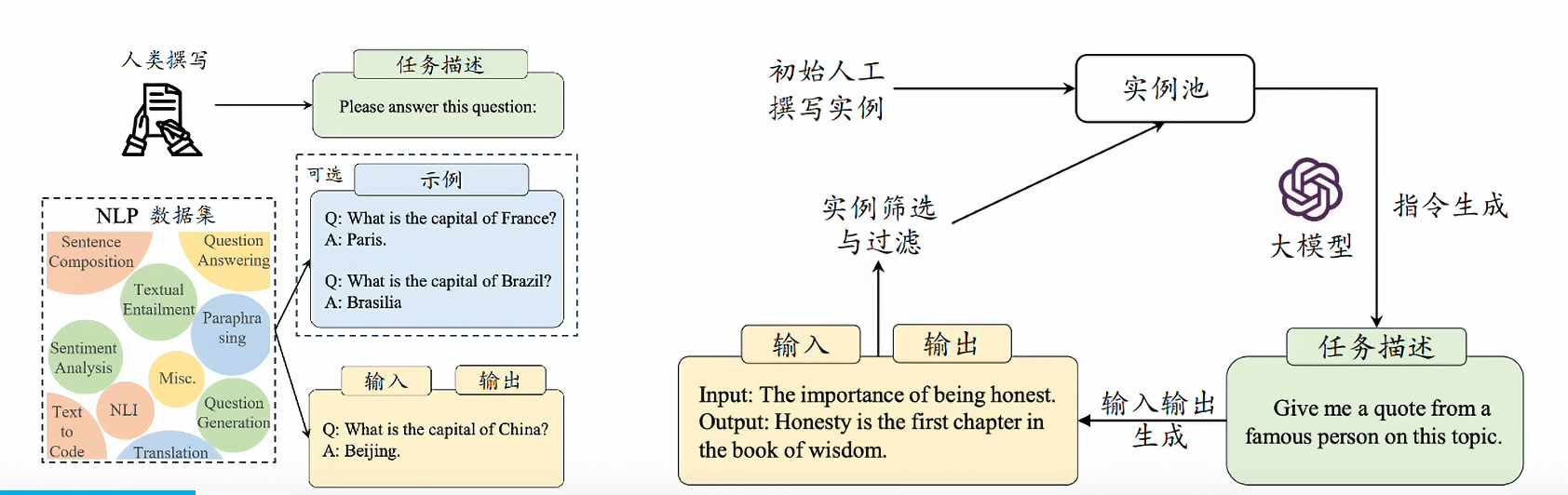
- 指令微调(Instruction Tuning)v 【有人也叫SFT】
- 使用输入与输出配对的指令数据对于模型进行微调
- 提升模型通过问答形式进行任务求解的能力
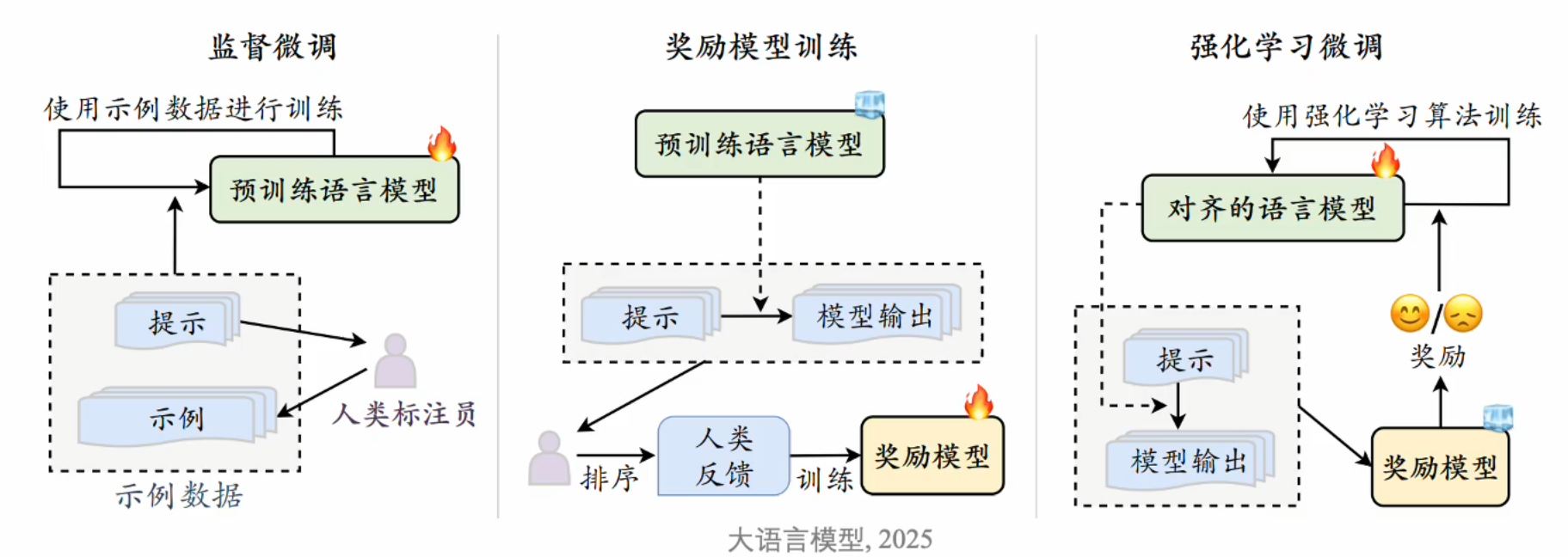
- 人类对齐(Human Alignment)
- 将大语言模型与人类的期望、需求以及价值对齐。
- 基于人类反馈的强化学习对齐(RLHF)。
扩展定律
什么是扩展定律
- 通过扩展参数规模、数据规模和扩大算力,大语言模型的能力会出现显著提升
- 扩展定律再本次大模型浪潮中起到了重要作用
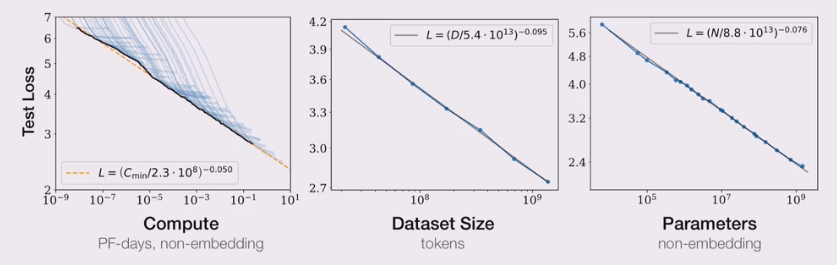
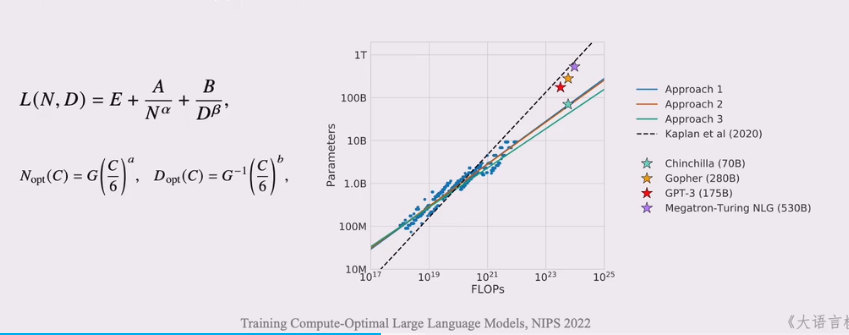
KM扩展定律
- OpenAI团队建立了神经语言模型性能与参数模型(N)、数据规模(D)和计算算力(C)之间的幂律关系
Chinchilla扩展定律
DeepMind团队于2022年提出另一种形式的扩展定律,旨在指导大语言模型充分利用给定的酸锂资源优化
深入讨论
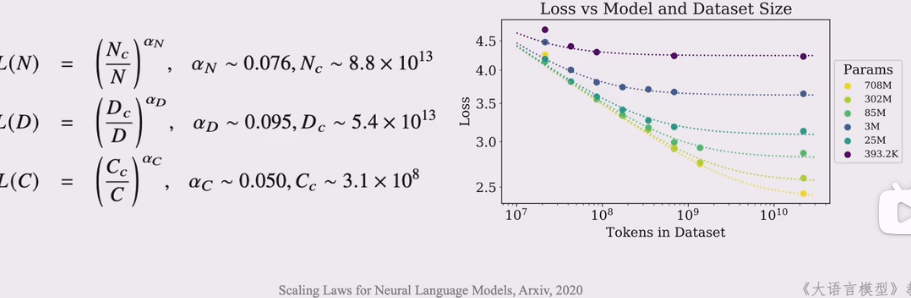
模型的语言建模损失可以进行下述分解
$L(x)=\underbrace{L_{\infty}}{\text {不可约损失 }}+\underbrace{\left(\frac{x{0}}{x}\right)^{\alpha_{x}}}_{\text {可约损失 }}$
可约损失: 真实分布和模型分布之间KL散度,可通过优化减少
不可约损失:真实数据分布的熵,无法通过优化减少
扩展定律可能存在边际效益递减
- 随着模型参数、数据数量的扩展,模型性能的增益将逐渐减小
- 目前开发数据已经接近枯竭,难以支持扩展定律的持续支持
可预测的扩展(Predictable Scaling)
- 使用小模型性能去预估大模型性能,或帮助超参数选择
- 训练过程中使用模型早期性能来预估后续性能
涌现能力
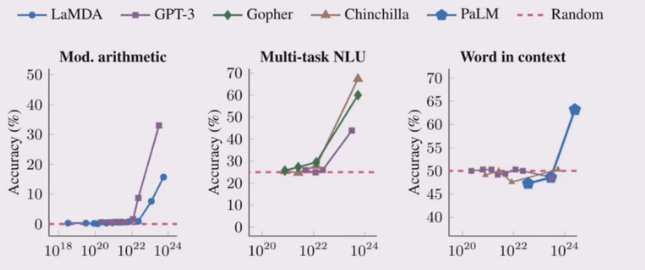
什么是涌现能力?
- 原始论文定义: 在小模型中不存在、但在大模型中出现的能力
- 模型扩展到一定规模时,特定任务性能突然出现显著跃升趋势,远超随机水平
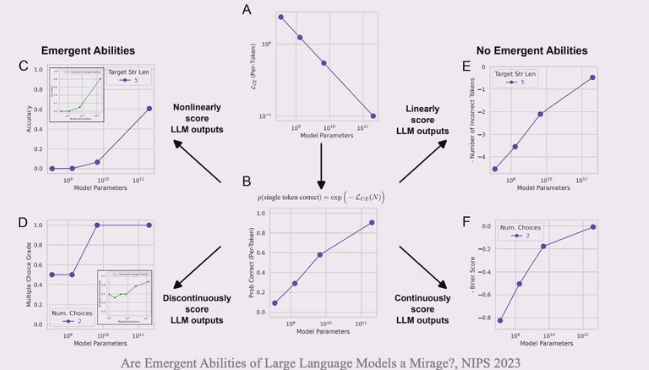
涌现能力可以部分归因于评测设置
本教程定义其为“代表性能力”,并不区分是否在小模型中存在
代表性能力
指令遵循(Instruction Following)
- 大语言模型能够按照自然语言指令来执行对应的任务
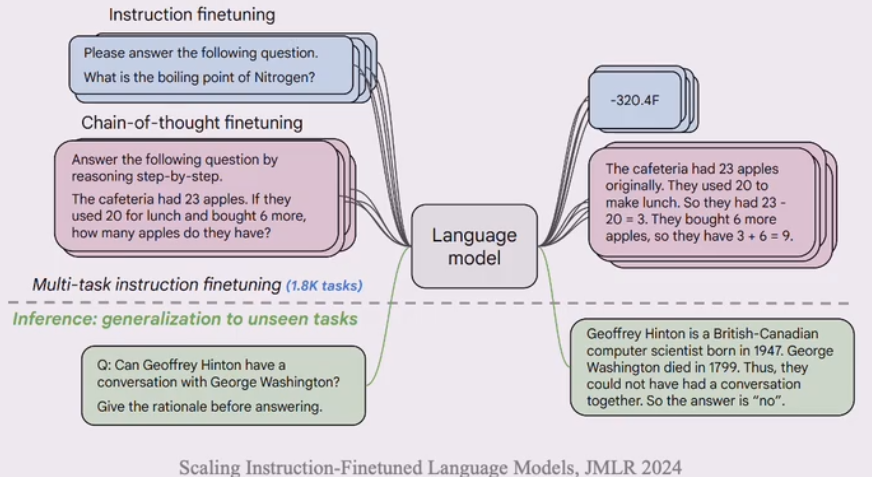
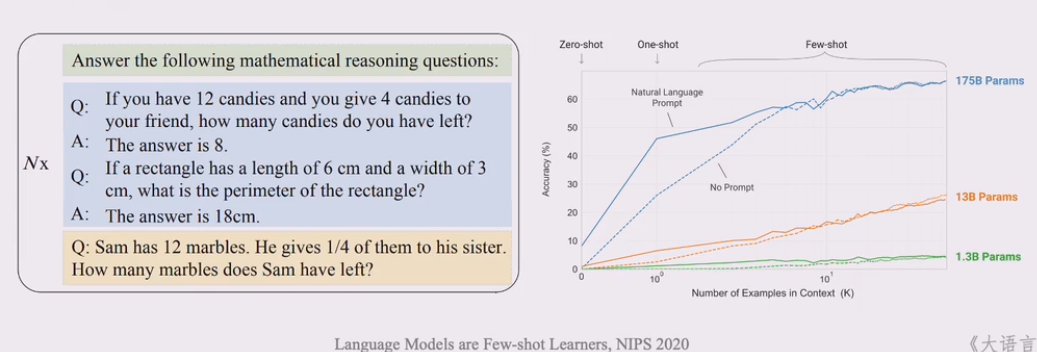
上下文学习(In-context Learning)
- 在提示中为语言模型提供自然语言指令和任务示例,无需显式梯度更新就成为测试样本生成预期输出。
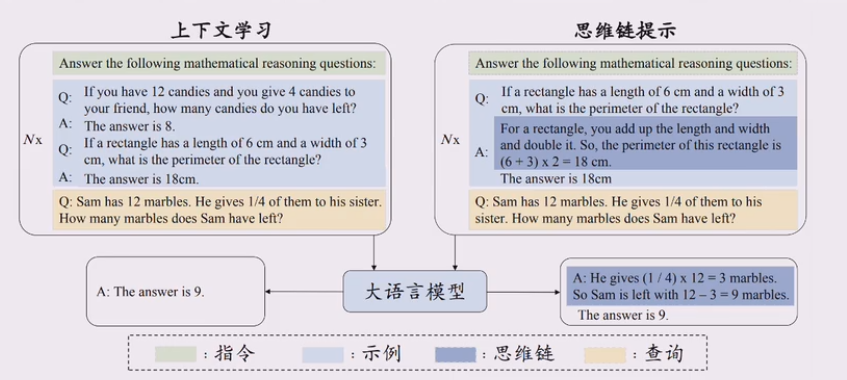
逐步推理(Step-by-step Resoning)
在提示中引入任务相关的中间推理步骤来加强复杂任务的求解,从而获得更可靠的答案
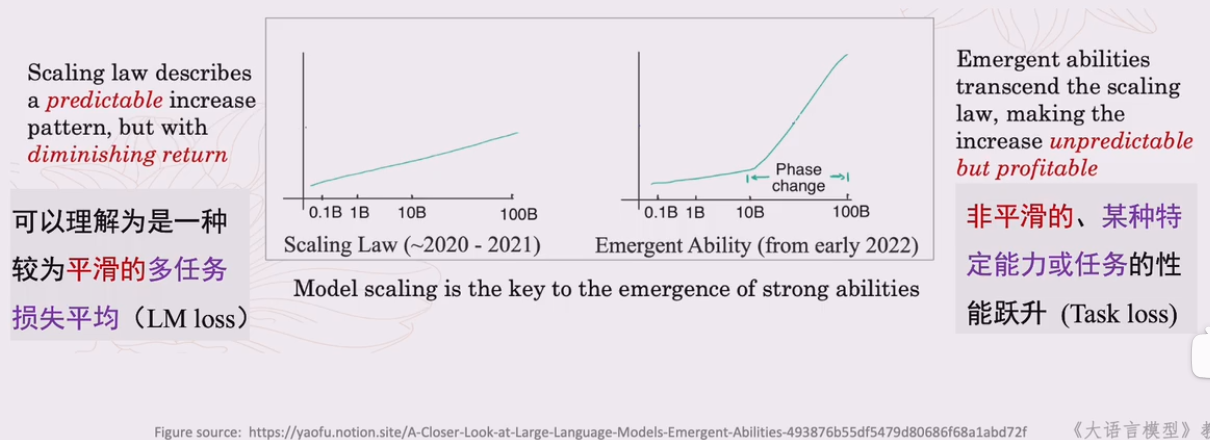
涌现能力与扩展定律的关系
涌现能力和阔扎定律是两种描述规模效应的度量方法
总结
大模型核心技术
- 规模扩展:扩展定律奠定了早期大模型的技术路线,产生了巨大的性能提升。
- 数据工程:数据数量、数据质量以及配置方法极其关键
- 高效预训练:需要建立可预测、可扩展的大规模训练架构
- 能力激发:预训练后可以通过微调、对其、提示工程等技术进行能力激活
- 人类对其:需要设计对齐技术减少模型使用风险,并进一步提升模型性能
- 工具使用:使用外部加强模型的弱点,拓展其neng'li
更新日志
2025/6/6 02:20
查看所有更新日志
84887-于579a4-于bb8a1-于